![[Deivid's Docs ~]#](https://deividsdocs.wordpress.com/wp-content/uploads/2015/05/gnulinuxdocs.png)
Un poco largo el titulo, sí, pero demuestra que en GNU/Linux tenemos mucho más que cat para tratar ficheros. Algunos de los comandos nombrados en el titulo son bastante básicos, otros envuelven una gran cantidad de opciones, unas comunes, otras más oscuras, en este pequeño repaso por los comandos más básicos de tratamiento de ficheros, veremos las opciones más ‘utilizadas’, y sus explicaciones junto con algunos ejemplos. Las opciones menos usadas generalmente o que envuelven modos de funcionamientos más especificos y concretos del comando, serán descritas pero de manera rápida. Espero, en un futuro, poder tratar cada uno de esos comandos con opciones más oscuras.
CAT
Cat, viene de concatenar, y es el típico comando que utilizamos para leer rápidamente un fichero de pocas líneas (syslog, no, por ejemplo), digamos que la función principal de CAT es la posibilidad de leer varios ficheros y enviar el resultado la salida estándar (STDOUT).
Por ejemplo:
$ cat f1.txt f2.txt
Contenido de F1
Contenido de F2
cat -E : muestra un $ al final de cada línea
cat -n : muestra el numero de lineas
cat -b : muestra el numero de lineas, pero no cuenta los espacios en blanco
cat -s : comprime varias líneas en blanco en una sola
cat -T : muestra los caracteres de tabulación como ^I
cat -v : muestra la mayoría de caracteres no imprimibles
Como curiosidad esta el comando tac que es igual que cat pero invierte el orden de salida de las líneas.
$ tac fichero1.txt
Línea 2
Línea 1
JOIN
El comando Join combina dos archivos comparando el contenido de los campos especificados en los mismo. Los campos suelen ser entradas separadas por espacios dentro de una línea, aunque se puede especificar otro carácter separador con la opción -t #, donde # es el carácter separador. Join puede ignorar mayúsculas y minúsculas con la opción -i. Ejemplo de uso de Join, por ejemplo tenemos dos archivos:
Archivo1.txt
555-2397 Beckett, Barry
555-5116 Carter, Gertrude
555-7929 Jones, Theresa
555-9871 Orwell, Samuel
Archivo2.txt
555-2397 unlisted
555-5116 listed
555-7929 listed
555-9871 unlisted
Con join obtendremos el siguiente efecto:
$ join archivo1.txt archivo2.txt
555-2397 Beckett, Barry unlisted
555-5116 Carter, Gertrude listed
555-7929 Jones, Theresa listed
555-9871 Orwell, Samuel unlisted
Por defecto, y como vemos en el ejemplo anterior, join, toma el primer campo para hacer las comparaciones, en este caso el campo de los números es el campo clave y es así que realiza la ‘mezcla’ de los 2 archivos, si queremos cambiar dicho campo clave , podemos utilizar el comando -1 #, donde # es el campo/columna del primer fichero que tendrá que comparar con el primer campo/columna del segundo fichero; si queremos, también podemos indicar que campo/columna queremos que se compare en el segundo fichero de la misma forma: -2 #. Por ejemplo:
$ join -1 2 -2 3 f1.tx f2.txt
De tal manera que se comparará el segundo campo/columna del primer fichero con el tercer campo/columna del segundo fichero. Además, recalcar que join necesita tener los 2 archivos ordenador para realizar la ‘mezcla’ de los mismos, en tal caso podríamos utilizar sort.
PASTE
El comando paste fusiona dos archivos, línea por línea, separando las líneas de cada archivo por tabulaciones, ejemplo:
$ paste listado.1.txt listado.2.txt
555-2397 Beckett, Barry 555-2397 unlisted
555-5116 Carter, Gertrude 555-5116 listed
555-7929 Jones, Theresa 555-7929 listed
555-9871 Orwell, Samuel 555-9871 unlisted
Si queremos seperar los dos archivos con otro tipo de caracter, podemos usar -d # –delimiter=#, donde # es el caracter
EXPAND
Este comando es utilizado para convertir tabulaciones en espacios. Por defecto reconoce 8 caracteres como una tabulación, se puede cambiar su funcionamiento con el parámetro -tabs=num o -t num, donde num es el numero de caracteres. Este comando a pesar de parecer muy sencillo puede resultar útil cuando tenemos un archivo que contiene tabulaciones y que queremos pasarle a un programa que no trabaja bien con las misma.
OD
Od se encarga de mostrar los archivos en base octal. Es posible utilizarlo para el manejo de salidas estándar que no están en ASCII y produzcan errores en el terminal, por ejemplo:
$cat /dev/urandom | od
Aunque la salida puede ser extremadamente confusa, es útil para saber la estructura de los archivos de datos:
$od listado.1.txt
0000000 032465 026465 031462 033471 041040 061545 062553 072164
0000020 020054 060502 071162 005171 032465 026465 030465 033061
0000040 041440 071141 062564 026162 043440 071145 071164 062165
0000060 005145 032465 026465 034467 034462 045040 067157 071545
0000100 020054 064124 071145 071545 005141 032465 026465 034071
0000120 030467 047440 073562 066145 026154 051440 066541 062565
0000140 005154
0000142
El primer campo de cada línea es un índice al archivo en octal. Los números restantes de cada línea representa los bytes del archivo. Podemos trabajar con distintas salidas con el comando od por ejemplo
SORT
Es utilizado para ordenar la salida de un comando, se puede ordenar por:
- Ignorar mayúsculas y minúsculas: -f o –ignore-case
- Ordenar por meses: -M o –month-sort, hace que sort ordene por las tres letras de abreviaturas de los meses que van desde JAN a DEC
- Ordenación numérica: -n o –numeric-sort
- Invertir el orden: -r o –reverse
- Campo de ordenación: por defecto se utiliza el primer campo, para cambiar el campo: -k campo o –key=campo (campo puede estar compuesto por dos campos numerados separados por comas para ordenar por varios campos)
SPLIT
Es utilizado para dividir un archivo en varias partes y dejar dichas partes en otros archivos. Tendremos que pasarle al comando un prefijo para el nombre de los archivos, a partir de nuestro prefijo irá creando archivos de la siguiente forma: Xaa, Xab, Xac.
Los archivos se pueden dividir por número de bytes o por número de líneas, a parte de otros métodos, el principal problema de dividir por bytes, es que podría darse el resultado de que se cortará una frase o palabra por la mitad. En el caso más básico lo mejor sería separar por líneas.
División por números de líneas: -l líneas o –lines=líneas
En el ejemplo siguiente se dividirá el fichero listado.1.txt 4 veces en función del numero de lineas. f1 es el prefijo con el que construye los siguientes 4 ficheros. Si no se le pasan el numero de lineas a sort dividirá el fichero cada 1.000.
$split -l 1 listado.1.txt f1
$ ls
f1aa f1ab f1ac f1ad listado.1.txt listado.2.txt
TR
El comando TR cambia caracteres individuales de la entrada estándar. La sintaxis es la siguiente:
$tr [opciones] GRUPO1 [GRUPO2]
Se especifican los caracteres que se quieren reemplazar en un grupo (GRUPO1) y los caracteres con los que se quieren reemplazar en un segundo (GRUPO2). El siguiente comando reemplazará todas las letras del grupo uno por las del grupo dos.
$tr BCT bct < listado.1.txt
555-2397 beckett, barry
555-5116 carter, Gertrude
555-7929 Jones, theresa
555-9871 Orwell, Samuel
El siguiente comando, tendrá una letra menos en el grupo 2 con lo cual cambiará la última letra del grupo 1 (T) por la última del grupo 2 (c).
$tr BCT bc < listado.1.txt
555-2397 beckett, barry
555-5116 carter, Gertrude
555-7929 Jones, cheresa
555-9871 Orwell, Samuel
Si queremos evitar esto podemos añadir la opción -t o –truncate-set1. Tr también acepta atajos como: todas las mayúsculas [:upper:], todas las minúsculas [:lower:], todos los números y letras [:alnum:]; además se pueden especificar rango de caracteres, por ejemplo A-M.
UNEXPAND
Unexpand trabaja igual que Expand, pero al revés, convirtiendo todos los espacios en tabulaciones. Por defecto reconoce 8 caracteres como una tabulación, se puede cambiar su funcionamiento con el parámetro -tabs=num o -t num
FMT
Con FMT aplicamos formato a un párrafo. Este comando es especialmente utilizado para textos con líneas exageradamente largas. Si se ejecuta sin parámetros el fichero se reduce a un ancho de 75 caracteres por línea, si desea variar este funcionamiento tendrá que hacerlo con la opción: –ancho -w ancho o –width=ancho.
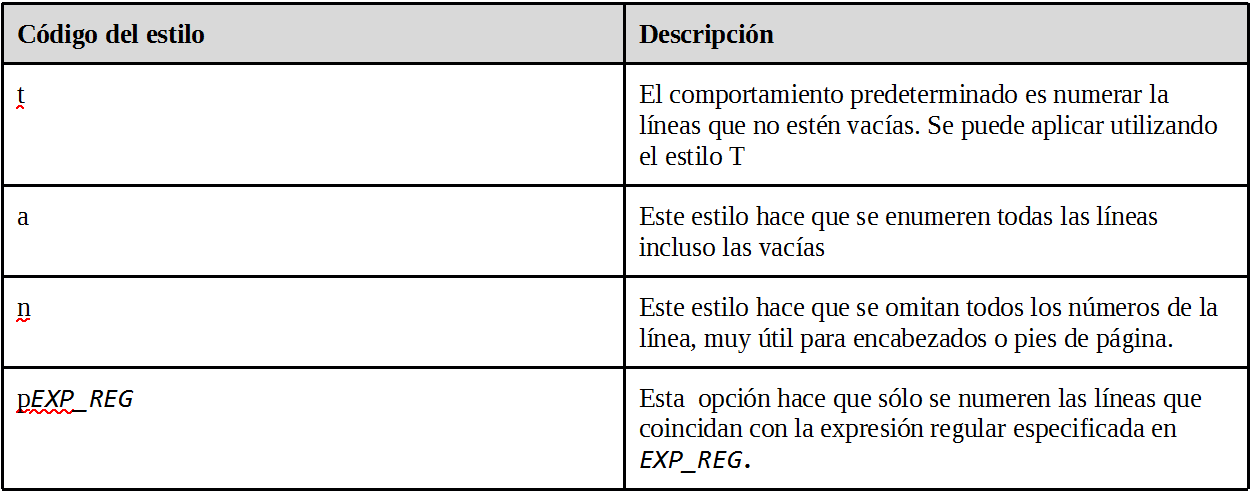
NL
Este comando sirve para numerar líneas, tiene muchas más opciones con las que se puede conseguir una salida más compleja que con un simple cat -b:
- Estilo de numeración del cuerpo: -b estilo, donde estilo es el código del formato de estilo, descrito abreviadamente.
- Estilo de numeración de encabezados y pies: -h estilo o -f estilo , para el encabeza y el pie respectivamente.
- Separador de páginas: -d=código, donde código es el código del carácter que identifica la nueva página
- Formato de números: -n formato, dónde formato es ln (justificado a la izquierda, sin ceros iniciales), rn (justificado a la derecha, sin ceros iniciales) o rz (justificado a la derecha, con ceros iniciales)
- Opciones de número de línea para páginas nuevas: -p nl no reinicializará el número de línea al llegar a una nueva página.
PR
PR es utilizado para preparar archivos para la impresión, se queda un poco anticuado, sí, pero quien sabe si nos pudiese venir bien en un momento determinado. Cuando le pasamos un fichero a PR, la salida que nos dará será el archivo paginado, con el nombre del fichero, y con la hora de creación en la cabecera. Este funcionamiento puede ser manipulado con las siguientes opciones:
- Salida con espacios dobles: -d o –double-spaces
- Utilizar saltos de página: por defecto pr separa las páginas utilizando un número fijo de líneas en blanco. Esto funciona si la impresora utiliza el mismo numero de lineas que espera pr. Si tiene problemas con esto, puede pasar las opciones: -F , -f o –form-feed, que hacen que pr imprima un carácter de salto de página entre las páginas.
- Definir longitud de página: -l líneas o –length=líneas
- Definir el texto de encabezado: -h texto o –header=texto. Sustituye el nombre de archivo.
- Omitir el encabezado: -t o –omit-header
- Definir margen izquierdo: -o caracteres o –indent=caracteres
- Ancho de página: este valor se suma a los 72 caracteres por defecto del ancho de la página. -w caracteres o –width=caracteres
Ejemplo: $cat -n /etc/profile | pr -dfl 25 -h “Fichero para apuntes” > f1.txt


No podias echiparlo mejor!!! crack!!
Gracias Oriol, ten un buen dia!